Why teams estimate
Nimble estimation of backlog items is a common feature of Agile frameworks that rely on fixed-iteration planning like Scrum and extreme programming (XP). Teams use estimates to make pragmatic guesses about questions like, “How many of the most important backlog items will fit into our next sprint?” or “How many more sprints might we need to finish a bundle of items that we think make up our next release?” Teams also use estimation to uncover differences in understanding about a particular piece of work, whether it’s a question of the objective or the method to build and validate it. But what’s different about Agile estimation is that the methods used tend to be a little vague. Instead of linear, universally understood quantities like hours or developer days, you’re more likely to find a team using a fuzzy, relative scale like story points or t-shirt sizes. Why? Because it keeps us from falling into some of the traps that pop up when we try to estimate with time.
How precise estimates can hurt teams
What’s the dictionary definition of estimate? A guess. That’s it. And often our estimates aren’t even ‘educated guesses’ because we’re doing new things all the time. The problem for Agile teams is that estimates are rarely ever treated as guesses. When a team says, “We estimate that building this feature will take…,” that information is instead treated as if the team had said, “Our scientifically-based promise is that building the feature will take…” Because the units of time-based estimates are precise, it’s easy to plug them in to traditional planning mechanisms like critical path task-based schedules or earned value management, and now those ‘guesses’ become the foundation of hardened expectations set with users, stakeholders, customers, and even ourselves. And what happens when those estimates are wrong? When something turns out to be easier or (more often) harder than we guessed it was going to be? All those planning behaviors come crashing down, people get angry, and teams get yelled at for being “bad at planning.”
Estimation accuracy over estimation precision
So partly to avoid the trap of treating guesses like promises, Agile teams tend to use estimations that are intentionally fuzzy. The methods used typically emphasize accuracy over precision. In this sense, precision means “how specific was our guess?” and accuracy means “was the guess close to what ended up happening?” Precision and accuracy in estimation are separate dimensions: an estimate could be both, one and not the other, or neither. For example, the tax data reported by my employer needs to be both precise (specific amounts of U.S. dollars and cents) and accurate (the amounts have to be true). My driver’s license, on the other hand, holds a very precise but inaccurate estimate of my weight (it’s a 3-digit number of pounds that likely bears no relation to my current actual weight). The cable company’s estimate of when they’ll be at my house (“sometime between 8am tomorrow and June”) is often neither accurate nor precise.
Clearly, inaccurate estimates aren’t very useful, no matter how precise they are. And if we dial down precision, accuracy gets a lot easier. Imagine an archer shooting arrows at a target. Accuracy would be a question of whether they can hit the bullseye. Precision would be a question of how wide the arrow is compared to the width of the bullseye. It’s far easier to hit a coin-sized bullseye if the arrow is as wide as a telephone pole than it would be with a needle-wide one.
Why not both?
But wouldn’t an estimate that’s both precise and accurate be the most useful?
Why don’t teams try to both? Because, unfortunately, for creative endeavors that are continually novel, elaborative, and complex, we can’t. If you look at the topic of estimating software development in hours (or any other linear unit of time) within the computer science literature, the findings are pretty stable going back more than 30 years now. Meta-analyses show that examine the correlation between the estimated and actual time to complete application development as a function of
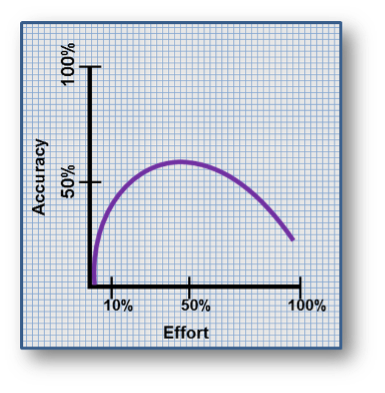 the proportion of total effort spent on estimating are quite depressing. Best case, if a team spends around half of their time estimating, they might generate estimates that have a 50% correlation to the eventual actual effort (in hours). That means that the actual will be somewhere between +/- 100% of the guess. And to come up with that guess, the team spent roughly half of their workday estimating instead of delivering value.
the proportion of total effort spent on estimating are quite depressing. Best case, if a team spends around half of their time estimating, they might generate estimates that have a 50% correlation to the eventual actual effort (in hours). That means that the actual will be somewhere between +/- 100% of the guess. And to come up with that guess, the team spent roughly half of their workday estimating instead of delivering value.
That’s a lot of time to spend generating estimates that feel precise but are so inaccurate as to be useless for pragmatic planning.
Size = effort + complexity + risk
The reason coming up with an accurate estimate for creative work is so difficult is because we’re bundling together several separate domains within a single guess. Effort is the one we’re usually focused on: some idea of how long an objective might take to complete. But another domain is complexity, or how many unknowns are involved in the objective. And a third domain could be called risk, or a sense of how much more effort could be potentially required if some of the unknowns don’t work out in our favor. Cognitively it’s very difficult for human brains to parse those dimensions out in a way that could be considered on some combination of linear scales. But if instead we back a couple of levels of precision and use fuzzy methods that are really ranking approaches, we can allow our minds to combine all three to make inelegant but accurate more-than less-than comparisons.
Imagine a team has been asked to estimate two backlog items: 1) develop a new version of an existing feature, and 2) patch a database to remove a vulnerability. Their consideration of the two items might run like this:
| New Feature
|
Database Patch
|
|
| Effort | “It’s like the one we did before, which took about a day and a half…”
|
“We just have to watch this script run for 15 minutes…”
|
| Complexity | “…but there’s one part that’s different that will take some figuring out…”
|
“…assuming our current configuration is compatible with the patch…”
|
| Risk | “…which might add another day if we have to build it from the ground up.”
|
“…and if it’s not we’d have to upgrade, patch, and then run full environment regression to find and fix what the upgrade may have broken.”
|
It would be very hard to come up with a meaningful, precise estimate comparison of the two items: the new feature would take 1-3 days, while the database patch would take either 15 minutes or a month of work. But it’s relatively easy to look at the two items and assess that the patch is more than the feature, largely for reasons of complexity and risk. How much more? How many times more? That’s too much precision to say with any accuracy, but we can simply say that it is more, or bigger, or a larger size.
How fuzzy estimates help teams
So that, in a nutshell, is the way that fuzzy estimates work, and why we use them in complex, creative work like software development. There are many different scales a team might use for the estimation, including story points (also called complexity points), powers of two, t-shirt sizes, and a host of others. All of them work essentially the same: they are methods for a group of people to make relative more-than/less-than comparisons of many items and come to some shared agreement about size that simultaneously considers effort, complexity, and risk.
How does this relative estimation help teams? In many important ways:
- It’s fast. Any time we learn something new about something we haven’t done yet, we can quickly re-assess and adjust its size if we need to. That means we can also give today’s best, most-informed guess about future work.
- It’s efficient for exposing unknowns. If one team member sizes something very small, while another person says it’s huge, then that’s a clear indication we don’t have a shared understanding yet of what is to be done or how. That means we can quickly identify gaps in knowledge or decision-making.
- It reinforces that estimates are guesses. By using fuzzier, less precise methods, we get to continually remind anyone who wants to use our estimates for planning that we’re constantly dealing with the unknown. That means stakeholders are often more receptive when we need to adjust scope or timelines to fit a new reality.
Want to learn more?
If you’re looking to find out more about how a Scrum team creates and uses relative estimation to plan Sprints and support Backlog Refinement, a great place to start would be a Certified ScrumMaster class!
If you’d like to know a Product Owner can use a Scrum Team’s estimates to plan and actively manage a Release, come check out our Certified Scrum Product Owner class!
If you’d like help adapting institutional behaviors in your organization that rely on traditional time-based estimation to use higher-accuracy relative estimates, come chat with our amazing Agile Coaches!
You Might Also Like
Is Your Team’s Sprint Planning Broken?
Scrum is a framework that operates in a rhythmic cadence called “sprints,” which are fixed...
What a Sprint Review Is… and Isn’t
The Scrum framework includes a pattern of five activities that allow a small team to...
Common Questions About Sprint Planning, Answered
The goal of sprint planning is to ensure the Product Owner (PO), Developers, and Scrum...